

导读:通过给照片添加肉眼看不出来的对抗性噪声,来蒙蔽人脸识别AI,达到保护隐私的效果。
本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
上回书说到,现在,对抗攻击的理念已经被应用到隐私保护领域:
通过给照片添加肉眼看不出来的对抗性噪声,来蒙蔽人脸识别AI,达到保护隐私的效果。

不过,就有好学的同学提出了这样的疑问,各种App基本都会对图片重新进行压缩,那这种照片「隐身衣」不就会因此失效吗?


最近,武汉大学国家网络安全学院就和Adobe公司合作,针对这个问题进行了研究, 并提出了一种适用于任意压缩方式的抗压缩对抗性图像生成方案。
也就是说,这是一身具有抗压缩能力的照片「隐身衣」。
即使经过处理的照片被社交平台中各种压缩算法改造一番,也依然能保持对抗性。比如,在微博上就可以达到90%以上的成功率。

抗压缩的照片「隐身衣」
一般来说,添加了微小扰动的对抗性实例,都会受到图像压缩方法的影响。
尤其是现在不同社交平台采用的压缩方法都是黑盒算法,压缩方法的变化也给对抗性实例的「抗压性」带来了不小的挑战。
论文一作王志波教授就指出:
在压缩算法未知或不可微的情况下,生成抗压缩的对抗性图像具有很大挑战性。
为了解决这样的问题,这项研究提出了抗压缩对抗框架ComReAdv。

具体而言,方案分为三个步骤。
步骤一:构建训练数据集
通过上传/下载的方式,获取大量原始图像和对应的压缩图像,构建训练数据集。
步骤二:压缩近似
利用原始图像-压缩图像对构成的数据集进行监督学习。
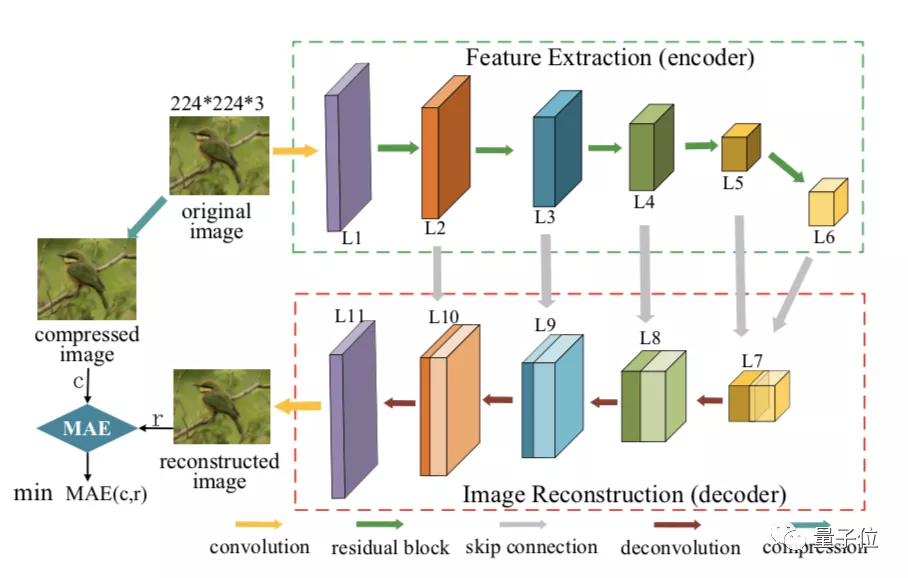
研究人员设计了一个基于编码-解码的压缩近似模型,称为ComModel。该模型被用于学习如何像黑盒压缩算法一样转换图像,以达到近似压缩的目的。
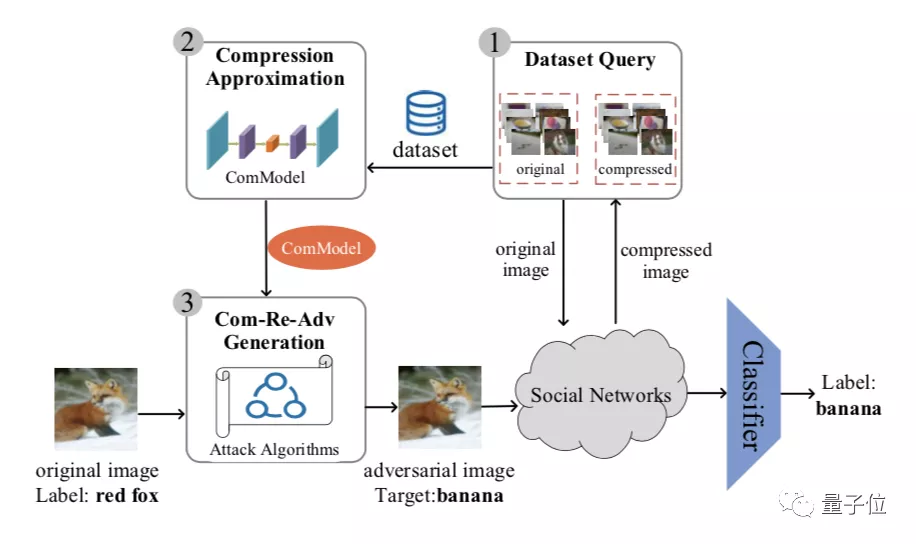
其中,编码器从原始图像中提取多尺度特征,如内在纹理和空间内容特征。
对应的,解码器对压缩后的对应图像进行由粗到细的重构,以模仿真实压缩图像的压缩效果。
通过最小化重构图像和真实压缩图像之间的平均绝对误差(MAE),训练后的ComModel可作为社交平台未知压缩算法的可微近似形式。
步骤三:抗压缩对抗性图像生成
构建优化目标,将ComModel融入到对抗性图像的优化过程中,并使用基于动量的迭代方法(MI-FGSM)进行优化,最终使得生成的对抗性图像具有较好的抗压缩能力。
研究人员表示,该方案不需要任何压缩算法的细节,仅根据适量的原图和压缩图的数据集,便能训练得到未知压缩算法的近似形式,并进一步生成相应的抗压缩对抗性图像,因此,该方案能应用于所有社交平台保护用户隐私。
实验结果
研究团队进行了本地仿真测试(JPEG、JPEG2000、WEBP)和真实的社交平台(Facebook、微博、豆瓣)测试。
本地仿真测试的结果显示,ComReAdv这一方法在「抗压缩」方面超越了SOTA方法,并且,可以有效抵抗不同的压缩方法,具有可扩展性。
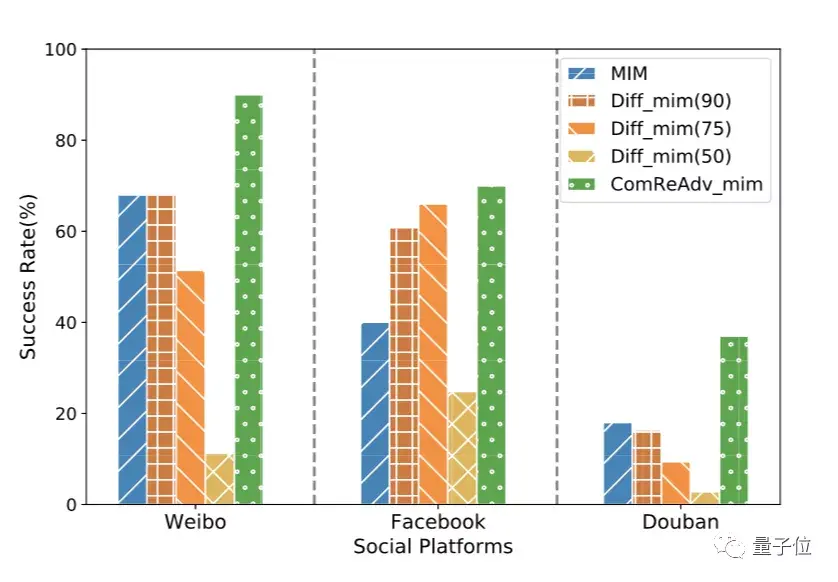
而真实社交平台测试的结果也表明,该方法能显著提高对抗性图像的抗压缩能力。
在被不同的压缩方法压缩后,误导Resnet50分类模型的成功率达到了最先进的水平,在微博上可以达到90%以上的成功率。
