

导读:AI的入门门槛,也让智能无所不及。
「无 AI,不科技」。在AI 产业逐步落地成熟的今天,AI 人才的争夺战已打响,甚至有不少网友预测,未来AI 开发将成为人人必备的技能之一。不过,现实来看,无论是 AI 三驾马车中的数据、算力、算法,还是细分而论的深度学习、机器学习、数据处理与统计、神经网络等,每一项技术的入门都需要花费大量的时间进行研究与实践,这无疑也对新时代下的开发者们提出了更高的挑战。
时下,为了助力高校人工智能领域人才培养及学科建设,并为业界百万的AI 专业人才缺口提供可持续性地输入,作为走在技术前沿的科技巨头华为,特发起《华为昇腾师资培训沙龙》系列活动,面向广大高校教师提供昇腾全栈全场景AI技术知识点培训,通过理论讲解和案例实操,希望能够更好地帮助未来的开发者群体降低 AI的入门门槛,也让智能无所不及。

日前,在昇腾师资培训沙龙·武汉场上,华为武汉研究所所长张继超表示,百万级AI 人才缺口的当下,AI 生态的构建不仅需要产业界的合作,同时也需要高校强有力的人才培养支持,华为将基于“沃土计算”2.0 计划与众多高校合作,构建智能基座。同时,华为也将秉持硬件开放,软件开源初心,使能合作伙伴。

华为武汉研究所所长 张继超
武汉理工大学计算机科学与技术学院院长熊盛武表示,在教育部、国家发展改革委、财政部印发的《关于“双一流”建设高校促进学科融合 加快人工智能领域研究所培养的若干建议》下,武汉理工大学实现了“两融合”即教科产融合和多学科融合,建设三院一体,以人工智能理论及算法为基础,服务于智能网联汽车、人工智能船舶与智能化长江航运、智能机器人与人工智能装备、康复机器人、人工智能新材料五大应用方向。

武汉理工大学计算机科学与技术学院院长 熊盛武
华为昇腾生态发展部部长刘鑫认为 AI 作为新的通用目的技术(GPT),将深刻推动社会发展进程。人工智能与任何行业的结合均可以催生一个新的产业诞生,本质上,人工智能的最终比拼的是科研能力和人才培养。在华为的 AI 战略中,高校生态是华为 AI 战略的关键组成部分,其构建昇腾知识体系,与高校联合课程开发,支撑专业必修课的改革,帮助更多的高校基于鲲鹏和昇腾进行教学。

华为昇腾生态发展部部长 刘鑫
人工智能时代已至
在为期两天的沙龙活动中,尤其值得开发者关注的是,在以 AI 战略赋能行业 AI 能力的同时,图灵解决方案架构师符秋杰也带来了《华为昇腾AI处理器架构》的主题分享,从华为AI 全栈解决方案、AI 处理器的软硬件架构及应用维度出发,全面剖析华为AI 强大计算力背后的技术。

图灵解决方案架构师 符秋杰
接下来,我们将一探华为全栈全场景 AI 解决方案背后的那些“秘密”硬核技术。
华为 AI 全栈解决方案全解析
还记得在第三届HUAWEI CONNECT 2018(华为全联接大会)上,首次发布华为 AI 战略与全栈全场景AI 解决方案,其中包含全球首个覆盖全场景人工智能的华为 Ascend(昇腾)系列处理器以及基于华为Ascend(昇腾)全栈技术的产品和云服务。
从技术角度来看,华为 AI全栈解决方案围绕端、边、云进行了全面的布局,主要可分为四大层面:
芯片层:Ascend处理器采用了面向张量计算的达芬奇架构,通过独创的16*16*16的3D Cube设计,每时钟周期可以进行4096个16位半精度浮点MAC运算,为人工智能提供强大的算力支持。基于统一的达芬奇架构,可以支持Ascend-Nano、Ascend-Tiny、Ascend-Lite、Ascend-Mini、Ascend-Max等芯片规格,具备从几十毫瓦IP到几百瓦芯片的平滑扩展,天然覆盖了端、边、云的全场景部署的能力。芯片使能层:其核心部分为CANN ,在2020年8月10日的HAI大会上华为重点发布了CANN3.0,统一了编程架构,支持多种计算架构和计算体系,支持后向兼容,具备极强的伸缩性和适应性,做到了端边云全场景协同。CANN3.0包含芯片算子库、高度自动化算子开发工具、TBE 算子开发方式等多项内容。框架层:2020年3月份,华为开源了支持全场景AI计算的框架MindSpore,其具有自主知识产权,核心优势可以降低 20% 核心代码,开发效率能提升50%,因其开源的特性,MindSpore 也拥有丰富的生态资源,同时兼容主流的TensorFlow、PyTorch、PaddlePaddle 等框架。应用层:作为一站式 AI 开发平台,ModelArts 覆盖机器学习、深度学习、强化学习应用全流程,它支持零AI 基础编码、可视化、秒级调度,能够帮助开发者快速定制化 AI 模型。
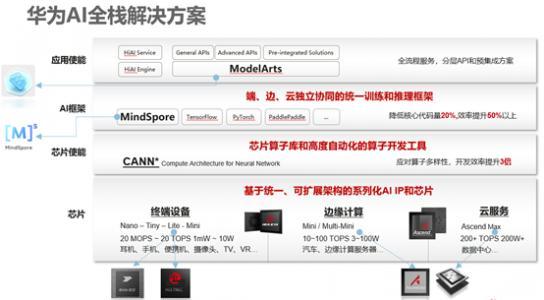
华为 AI 全栈解决方案
昇腾 AI 处理器硬件架构
在硬件层面上,华为于 2018年发布了推理AI处理器Ascend 310,2019年发布了训练 AI 处理器Ascend910。
时下,Ascend310 常被用于推理场景中,其整数精度为 16 Tera-OPS,功耗 8W,制程为 12nm。相比之下,训练场景中处理器Ascend 910,整数精度为 512 Tera-OPS,功耗为 310W,制程是7nm。
彼时,Ascend910带着“全球已发布的单芯片计算密度最大的 AI 芯片”、 以及Ascend 310作为“面向计算场景最强算力的 AI SoC” 光环面世,那么,它们在硬件上究竟是如何实现的,软件上又有哪些技术领先性?
Ascend 310 硬件逻辑架构
细分来看,Ascend310 硬件逻辑架构由五大核心构成:
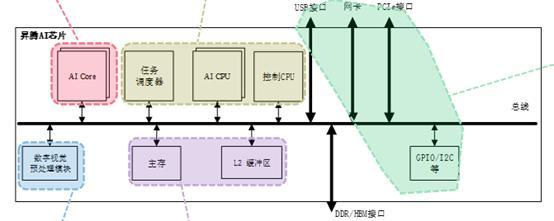
Ascend 310硬件逻辑架构图
AICore:作为昇腾 AI 芯片的计算核心,AI Core 负责执行矩阵、向量、标量计算密集的算子任务。Ascend 310 集成了2 个 AI Core。ARMCPU:Ascend 310 -集成了8个 ARM A55处理器。A55 主要分为两个部分,一部分为 AI CPU,负责执行不适合跑在AI Core上的算子(承担非矩阵类复杂计算);一部分部署为专用于控制芯片整体运行的控制CPU。两类任务占用的CPU核数可由软件根据系统实际运行情况动态分配。DVPP:在音视频编解码方面,Ascend 310 内部搭载了 DVPP 数字视觉预处理模块,进行编解码、压缩等预处理操作。Cache&Buffer:如果想要支撑 AI CPU和控制 CPU的正常工作,当然也离不开 Cache&Buffer 模块。其中,SoC片上有8MB L2 buffer,专用于AI Core、AI CPU,提供高带宽、低延迟的memory访问。芯片还集成了LPDDR4x控制器,为芯片提供更大容量的DDR内存。互连总线:Ascend 310 不仅支持PCIE3.0、RGMII、USB3.0等高速接口,也支持GPIO、UART、I2C、SPI等低速接口。Ascend 910硬件逻辑架构
Ascend 910 具备领先性,不仅是因为它集成了 32 个 AI Core,而且它的 CPU 也有增强,使用的是 16个TaishanV110 Core(4个Core构成一个Cluster)。
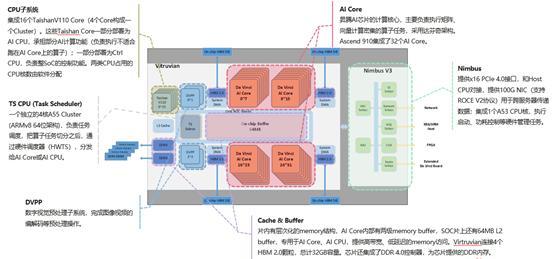
Ascend 910硬件逻辑架构图
在 TS CPU 层面,Ascend 910 除了有一个 4 核的 A55 Cluster作为软核 之外,还有一个HardwareTS,专门给AI Core 使用。简而言之,软硬核结合模式为性能带来极大地提升。
相比 Ascend310,在 SoC片上,Ascend 910存储有所不同,除了拥有64 MB L2 buffer之外,Virtruvian还连接了4个HBM 2.0颗粒。另外,Ascend910 的 Nimbus 部分集成了 1 个A53 CPU核,用来执行启动、功耗控制等硬件管理任务。在硬件上,这相当于是黑匣子功能,不仅可以提供软件异常定位手段,而且可以记录硬件异常场景的关键信息。
值得注意的是,通过两张架构图的对比,我们也不难看出 Ascend 310 和 Ascend 910 实际上是共架构。即它们的 SoC 只有处理器版本,以及 AI Core、计算单元、存储单元、带宽资源的不同,其他任务功能都非常类似。
那么,这个共同的架构——DaVinci达芬奇架构,它的内部构成又是什么样的呢?别急,我们将一探究竟。
Da Vinci达芬奇架构
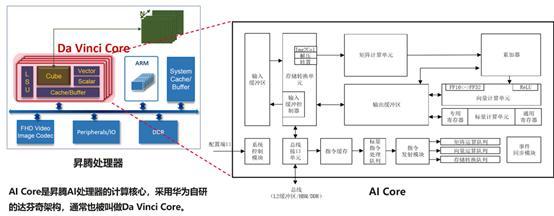
对于达芬奇架构的工作机制,通过上图,我们可进行速览。首先通过总线接口单元(内置高速总线),将数据搬到输入缓冲区,进而基于存储转换单元分别将左右矩阵填满,再送入矩阵乘加的累加器运算,运算结果判断是否需要做ReLu,如果需要 ReLu,送入向量计算单元随路处理,并将最终结果回传到输出缓冲区。
在该过程中,DaVinci Core内部被细分成很多单元,其中有三个重要部分:计算单元、存储系统,控制单元。
计算单元
计算单元又包含了三种基础计算资源,分别为矩阵计算单元、向量计算单元和标量计算单元,而它们对应的是矩阵、向量和标量三种常见的计算模式。
矩阵计算单元在达芬奇架构中,矩阵计算单元和累加器主要完成矩阵相关运算。一拍完成一个fp16 的 16x16 与 16x16 矩阵乘(4096),如果是int8输入,则一拍完成 16*32 与32*16 矩阵乘(8192)。
向量计算单元向量计算单元主要包含FP16/FP32/Int32/Int8等数据类型的计算。一拍可以完成两个128长度fp16类型的向量相加/乘, 或者64个fp32/int32类型的向量相加/乘。
标量计算单元标量计算单元相当于一个微型 CPU,控制整个 AI Core 的运行,完成整个程序的循环控制、分支判断,可以为Cube/Vector 提供数据地址和相关参数的计算,以及基本的算术运算。
简而言之,标量计算单元非常灵活,向量计算单元相对高效,矩阵计算单元具有高密性的计算。
存储系统
AI Core 的存储系统由存储单元和相应的数据通路构成,即可以把片外资源和片内资源形成一个通路。在存储单元部分,由存储控制单元、缓冲区和寄存器组成。其中输入缓冲区用来暂时保留需要频繁重复使用的数据,不需要每次都通过总线接口到AI Core的外部读取,从而在减少总线上数据访问频次的同时也降低了总线上产生拥堵的风险,达到节省功耗、提高性能的效果;而输出缓冲区,可以用来用来存放神经网络中每层计算的中间结果,从而在进入下一层计算时方便地获取数据。这也是该存储系统的两大优势所在。
控制单元
控制单元的作用就是为了保证整个片上的资源得到一个最优的性能。它主要由系统控制模块、指令缓存、标量指令处理队列、指令发射模块、矩阵运算队列、向量运算队列、存储转换队列和事件同步模块构成。
昇腾 AI 处理器软件架构
昇腾 AI 处理器的软件为硬件性能提升打下了扎实的基础,且为开发者提供了计算资源、性能调优等运行框架以及功能丰富的工具。从昇腾 AI 处理器软件逻辑架构方面,可将其分为三层:
计算资源层,主要是实现系统对数据的处理和对数据的运算执行。在计算资源层中,有几类不同的可执行的硬件单元,如 AICore,可执行 NN 类算子;AI CPU,可执行CPU算子;DVPP,可进行视频/图像编解码、预处理。除了计算设备之外,其实还有通信链路的存在。从上文可知,昇腾处理器其实是共架构的,而这不仅是芯片架构是公共的,在训练和推理的软件架构也是一致的,因此,虽然在面向不同场景处理器所执行的逻辑不同,但是在设计整个架构时,华为进行了统一,由此在计算资源层也加入了PCle、HCCS、RoCE通信链路。
芯片使能层,实现解决方案对外能力开放,以及基于计算图的业务流的控制和运行。这实际上是对应的是上文提到的 CANN 3.0,包含了开放编程框架AscendCL 昇腾计算语言库,其提供Device/Context/Stream/内存等的管理、模型及算子的加载与执行、媒体数据处理、Graph管理等API库,供用户开发深度神经网络应用;图优化和编译;算子编译和算子库,其中算子库有两种,一种是CCE,一种是 TBE;数字视觉预处理;以及执行引擎等能力。
应用层,包括基于 Ascend 平台开发的各种应用,以及 Ascend 提供给用户进行算法开发、调优的应用类工具。在华为 AI 全栈的软件解决方案上,昇腾AI 处理器的软件架构由若干子系统组成,如:
ACL 子系统:提供Device管理、Context管理、Stream管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等C++ API库供用户开发深度神经网络应用,通过加载模型推理实现目标识别、图像分类等功能;GE 子系统:GE作为图编译和运行的控制中心,提供运行环境管理、执行引擎管理、算子库管理、子图优化管理、图操作管理和图执行控制。FE子系统:为了业务的编排,抽象出执行引擎FE。它是一个逻辑概念,里面分三个部件:控制引擎、计算引擎、IO引擎,每个部件中都包含有算子库。AICPU子系统:主要提供了AICPU算子编译(部署在Host)和AICPU(部署在Device)两大功能。其中Host 是指昇腾AI处理器所在硬件设备相连的x86服务器、ARM服务器或者 WindowsPC。Device是指集成了昇腾 AI 处理器的设备。Host和Device可以在一个硬件实体上,也可以分布在不同的硬件实体上,此处是逻辑概念。HCCL子系统:集合通信对外提供集合通信算子,支持网卡及集群不同节点间的RoCE 传输功能,为分布式训练中不同 NPU 之间提供高效的数据传输能力。TBE子系统:提供了基于TVM 框架的自定义算子开发能力,通过TBE提供的API和自定义算子编程开发界面可以完成相应神经网络算子的开发。Runtime&TS 子系统:Runtime 为神经网络的任务分配提供了资源管理通道;TS 负责将 Runtime 分发的具体任务进一步分发到 AICPU 上。DVPP子系统:数字视觉预处理模块(DVPP)作为整个软件流执行过程中的编解码和图像转换模块,为神经网络发挥着预处理辅助功能。在应用开发实践中,开发流程具体可参考如下:
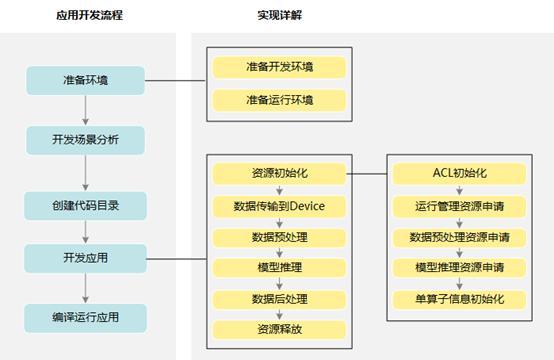
华为旨在为开发者打破 AI壁垒,帮助业界构筑更强 AI 算力平台
对于想要入门 AI 的开发者及从业者而言,可以通过MindX DL深度学习和MindX Edge智能边缘等平台,结合 Atlas 200、Atlas 200DK(开发者套件)、Atlas 900 AI训练集群等AI解决方案能够实现快速上手。与此同时,华为还推出了支撑全流程开发的工具链 MindStudio,方便更多的开发者进行算子开发、模型训练与模型推理等应用开发。
如果觉得内容还没有吃透,亦或是想要了解更多华为昇腾相关技术实践,别担心,“华为昇腾师资培训沙龙”还将在上海、南京、成都分别展开。

