

导读:为了改善目标检测性能,在构建数据增强器时,经常会使用一种称为 Cutout 的正则化技术。
与其他目标检测问题相比,自动驾驶本身有着特殊性。那么,在自动驾驶的训练中,沿用一般的数据增强手段是否有较好的效果呢?本文介绍分享 DeepScale 深度学习软件工程师 Matthew Cooper 在针对该问题的一些实验和探讨。
DeepScale 从 2019 年起由于被特斯拉收购的消息而备受关注,其旨在帮助汽车制造商使用大多数汽车中标准的低功率处理器来提供非常精确的计算机视觉,专注于开发自动驾驶汽车的深度神经网络。而在深度神经网络应用中,数据可以通过多种方式进行扩充,以避免过度拟合,从而提高模型检测性能。
1. 图像增强实验与结果
为了改善目标检测性能,在构建数据增强器时,经常会使用一种称为 Cutout 的正则化技术。简而言之,Cutout 会在图像中使随机放置的正方形变黑。

Cutout 应用于 CIFAR-10 dataset 中的图像
一般情况下,Cutout 可以显著提高视觉应用的准确性。但是,当将其应用于这些数据时,我们的检测 mmAP 降低了。我们搜索了这个问题后惊讶地发现,我们使用的所有增强器都极大地损害了检测性能。
在探索的开始,我们使用了 Filp(翻转)、Crop(裁剪)和权重衰减正则化,这些都是用于目标检测的常用方案。通过研究,我们发现这些数据在我们的数据集上均会损害检测性能。而删除这些增强器可使网络的初始性能提高 13%mmAP 。(mmAP 是 COCO 目标检测挑战中的默认评估指标)
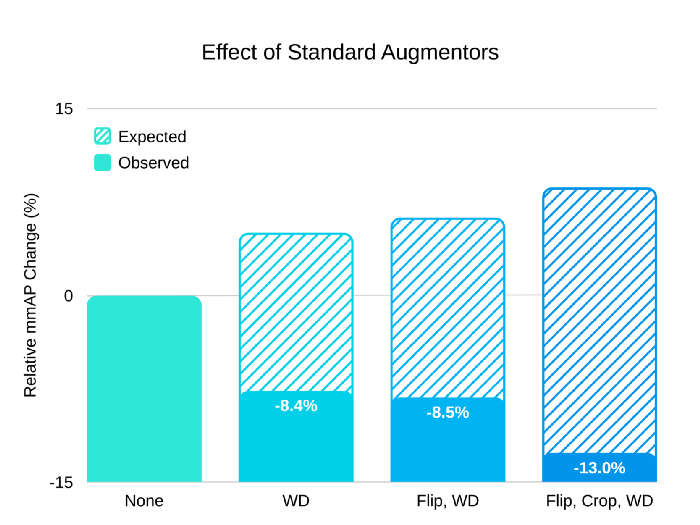
目标检测常用方案的效果
通常,我们希望使用权重衰减、Flip 和 Crop 来将性能提高几个点,如上图中虚线所示。但是,在这次的案例中,这些增强器分别对 mmAP 造成 8.4%、0.1%和 4.5%的损害。删除所有增强器可将整体性能提升 13%。
那么,为什么这些标准的增强器会损害检测性能呢?为了解释这些,我们要从根本原理来重新审视图像增强的想法。
2、为什么使用数据增强?
过度拟合是深度神经网络的常见问题。神经网络非常灵活;但是,考虑到常见数据集的大小,它们通常会被过度参数化。这将导致一个模型,该模型学习数据集中的“噪声”而不是“信号”。换句话说,他们可以记住数据集的意外属性,而不是学习有意义的常规信息。结果,当提供新的实际数据时,过拟合网络无法得到正确的结果。
为了解决过度拟合问题,我们经常选择扩充训练数据。扩充图像数据的常用方法包括水平随机翻转图像(Flip)、改变其色相(色相抖动)或裁剪随机部分(Crop)。

原始长颈鹿图像(左上方)、Flip(右上方)、色相抖动(左下方)、Crop(右下方)。虽然进行了不同的变换,但每个图像依然都是长颈鹿。
诸如 Flip、色相抖动和 Crop 之类的增强器有助于消除过度拟合,因为它们提高了网络的泛化能力。如果训练网络以识别面向右的长颈鹿并在面向左的长颈鹿的翻转图像上进行训练,则网络将知道长颈鹿是长颈鹿,而不管朝向如何。这就使得网络正确学习有关长颈鹿的相关信息(如棕色斑点毛皮),也能正确地排除一般信息。
诸如 COCO 目标检测挑战之类的公共数据集一般具有泛化的需求。由于这些数据集包含从多种来源聚合而来的图像,这些图像是在不同条件下从不同的相机拍摄的,因此网络需要概括出许多因素才能发挥出色的性能。网络需要应对的一些变量是:光、比例、摄像机固有特性(如焦距,主点偏移和轴偏斜)以及摄像机外部特性(如位置、角度和旋转)。通过使用数据增强器,我们可以训练网络来概括所有这些变量,就像在上一个示例中我们能够概括长颈鹿的方向一样。

来自 COCO 数据集的这些示例是使用不同的相机,不同的角度,比例和姿势拍摄的,因此有必要学习这些属性的不变性以在 COCO 目标检测中表现良好。
3、为什么自动驾驶汽车的数据不一样?
与来自 COCO 和其他公共数据集的数据不同,自动驾驶汽车收集的数据非常一致。
汽车通常相对于其他车辆和道路物体具有一致的姿势。此外,所有图像都来自相同的摄像机,安装在一样的位置和角度。这意味着同一系统收集的所有数据都具有一致的相机属性,例如上面提到的外部特征和固有特征。我们可以使用与量产时相同的传感器系统来收集训练数据,因此自动驾驶汽车中的神经网络不必担心这些属性的泛化。因此,适应系统的特定摄像机属性实际上可能是有益的。

这些来自 Berkeley Deep Drive 数据集(https://bdd-data.berkeley.edu/)中每个汽车的示例都是从同一摄像机以相同的角度和姿势拍摄的。它们还具有相同的伪影,例如挡风玻璃反射和每帧右下角的物体。
由于自动驾驶汽车数据具有一致性,这导致使用一般数据增强器(例如 Flip 和 Crop)对性能的损害超过其帮助。原因很简单:翻转训练图像是没有意义的,因为摄像头将始终处于相同角度,并且汽车将始终位于道路的右侧(因国家而已)。汽车几乎永远不会在道路的左侧,摄像头也永远不会翻转角度,因此对翻转数据进行训练会导致模型过度包含一些不会发生的场景。同样,裁剪具有移动和缩放原始图像的效果。由于汽车的摄像头将始终位于相同位置,因此这种移动和缩放会导致网络会浪费其对不相关场景的预测能力。
4、如何改进?
现在,我们理解了自动驾驶汽车数据具有一致性,导致了之前那些增强器不太理想的结果。接下来,我们来看看是否可以利用这种一致性来进一步提高性能。
在引入任何新的扩充器之前,我检查了我们的数据集以查看是否可以在数据级别进行任何改进。我们的训练集最初包括来自两个广角相机和一个带变焦镜头的相机的图像。变焦镜头产生类似于 Crop 的缩放和移动效果。在测试时,我们仅使用广角相机,因此对缩放图像进行训练会使得网络过于笼统。我发现,从训练集中删除缩放图像可以大大提高 mmAP。这证实了我们的假设,即训练集和测试集之间的一致性对于性能至关重要。
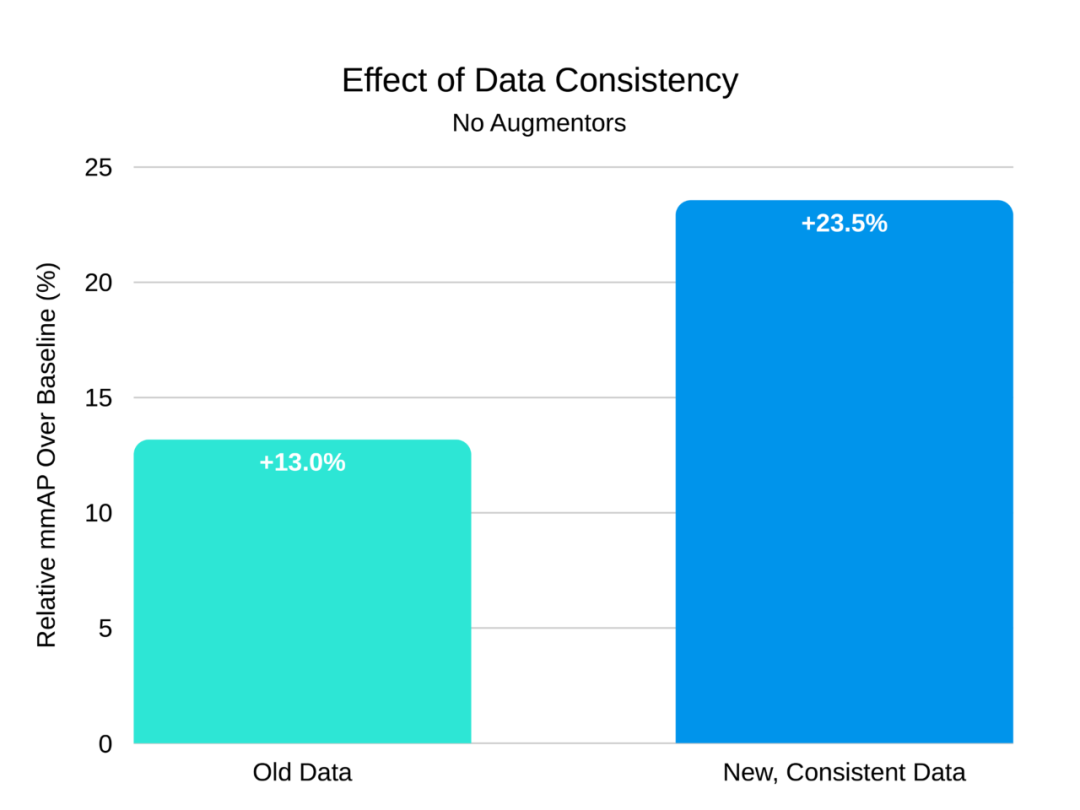
删除原始图像增强器后,我们在新的更一致的新数据集上进行了训练和测试。相对于原始方案,mmAP 额外提高了 10.5%。
之后,我们考虑了可以在不更改相机属性的情况下更改训练数据的增强器。我在该项目开始时实施的 Cutout 增强似乎是一个不错的选择。与 Flip 和 Crop 不同,Cutout 不会以严重影响相机属性的方式(即通过翻转,移动或缩放)来更改输入。取而代之的是,Cutout 可以模拟障碍物。障碍物在现实世界的驾驶数据中很常见,而障碍物的不变性可以帮助网络检测部分被遮挡的物体。

障碍物在现实世界的驾驶数据中很常见。在此图像中,两个行人挡住了我们对警车的视野,而大包挡住了我们对行人的视野。
色相抖动(Hue jitter)还可以在不影响相机属性的情况下帮助泛化。色相抖动只是将输入的色相移动一个随机量。这有助于网络对颜色进行泛化(例如,红色汽车和蓝色汽车都应被检测为汽车)。不出所料,Cutout 和色相抖动都改善了在新数据集上的性能。
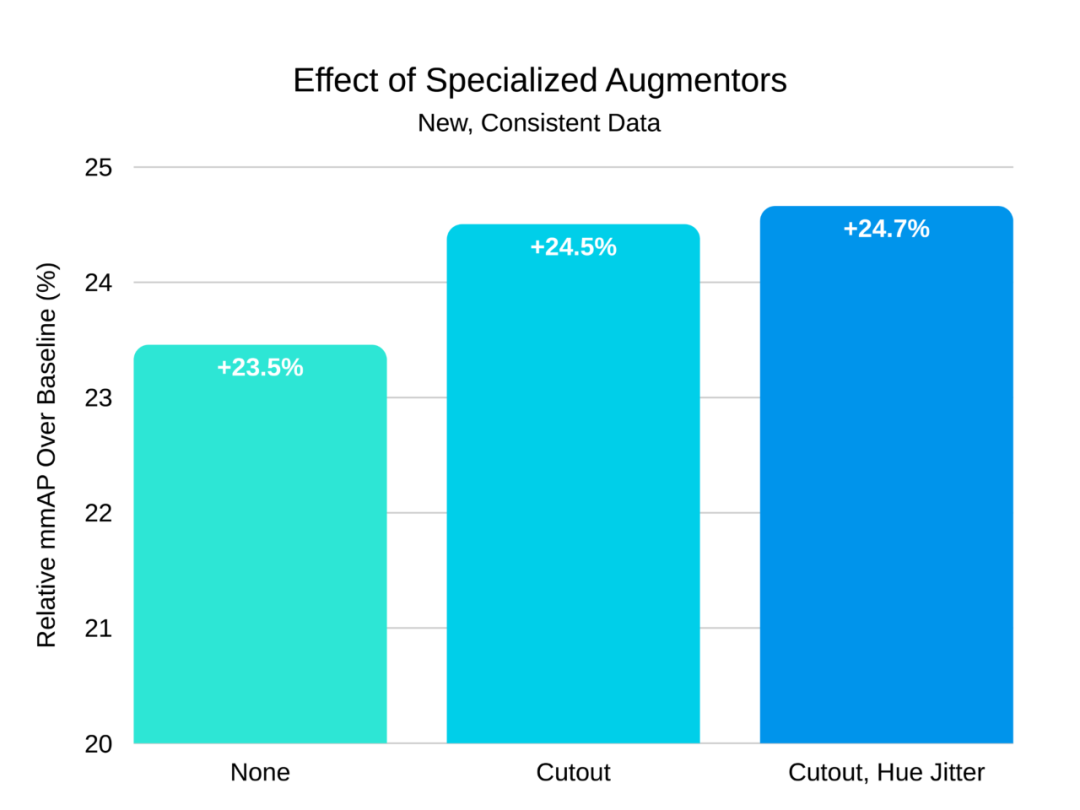
向新数据集中添加 Cutout 和色相抖动增强,相对 mmAP 分别增加了 1%和 0.2%。这比原始方案(即旧数据集上的 Flip、Crop 和权重衰减)提高了 24.7%。
值得注意的是,这些增强技巧不适用于包含来自不同相机类型、不同角度和比例的图像数据集。为了证明这一点,我们通过随机翻转和剪裁创建了具有多种相机属性的测试集。不出所料,在更通用的数据集上,我们新的增强方案的性能比原始的一般增强器差。
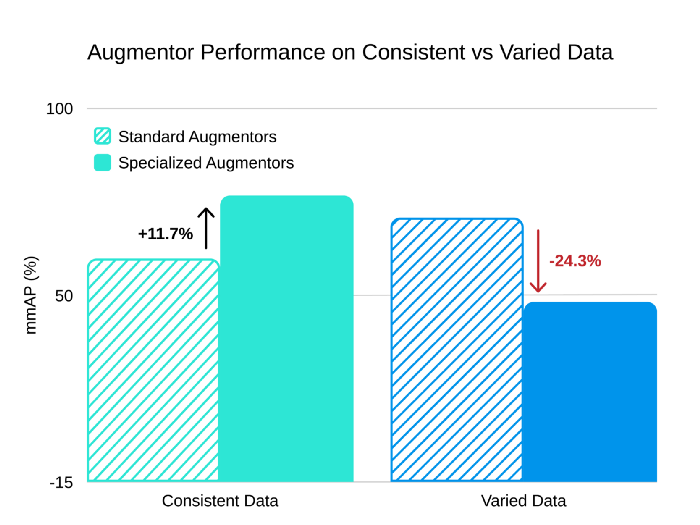
当应用于具有一致性的自动驾驶汽车数据时,我们的新增强方案(Cutout 和色相抖动)与一般增强方案(Flip、Crop 和权重衰减)相比,mmAP 提升了 11.7%。但是,当我们将其应用到更多样化的数据时,与一般方案相比,其结果会下降 24.3%。
5、最后
Flip 和 Crop 等增强方式在很多研究工作上取得了广泛的成功,以至于我们从没想过要质疑它们对我们特定问题的适用性。当我们从根本原理重新审视增强概念时,很明显我们可以做得更好。机器学习领域有许多类似的“通用最佳实践”,例如如何设置学习率,使用什么优化器以及如何初始化模型。对于机器学习工程师来说,不断重新审视我们关于如何训练模型的假设非常重要,尤其是在针对特定应用进行构建时。学术界尚未对此类问题进行探讨,而通过以崭新的眼光看它们,我们可以极大地改善机器学习的实际应用。
参考信息
https://towardsdatascience.com/when-conventional-wisdom-fails-revisiting-data-augmentation-for-self-driving-cars-4831998c5509
